Rust Crawling 준비
러스트 백엔드 스켈레톤을 그런대로 만들기까지 한 달 가까운 시간을 흘려보내버렸습니다. 그 사이 며칠은 원서를 쓰기도 했고, 면접이나 대회 참가로 진전이 없는 날도 더러 있었습니다. 아르바이트로 하루종일 컴퓨터엔 손도 대지 못한 날도 있었습니다. 이제는 작동하는 최소 단위의 스켈레톤을 만들었으니, 본격적으로 쓸모있는 프로그램을 만들어볼 차례입니다.
계획은 그리 거창한 것이 아니고, 어떤 영화를 검색하면 거리 순으로 가장 가까운 영화관들을 찾아주는 웹페이지를 생각하고 있습니다. 이걸 만들기 위해서는 양질의 정보를 확보할 필요가 있습니다. 확인해본 결과 KOBIS에서 몇 가지 영화관 API를 제공하고 있으나, 제가 원하는 형태의 API는 없는 것 같습니다. 대신 정보를 제공하는 페이지는 여럿 있습니다.
일단 임의의 지역에서 어떤 영화를 상영하는지를 찾을 수 있는 페이지는 있습니다.
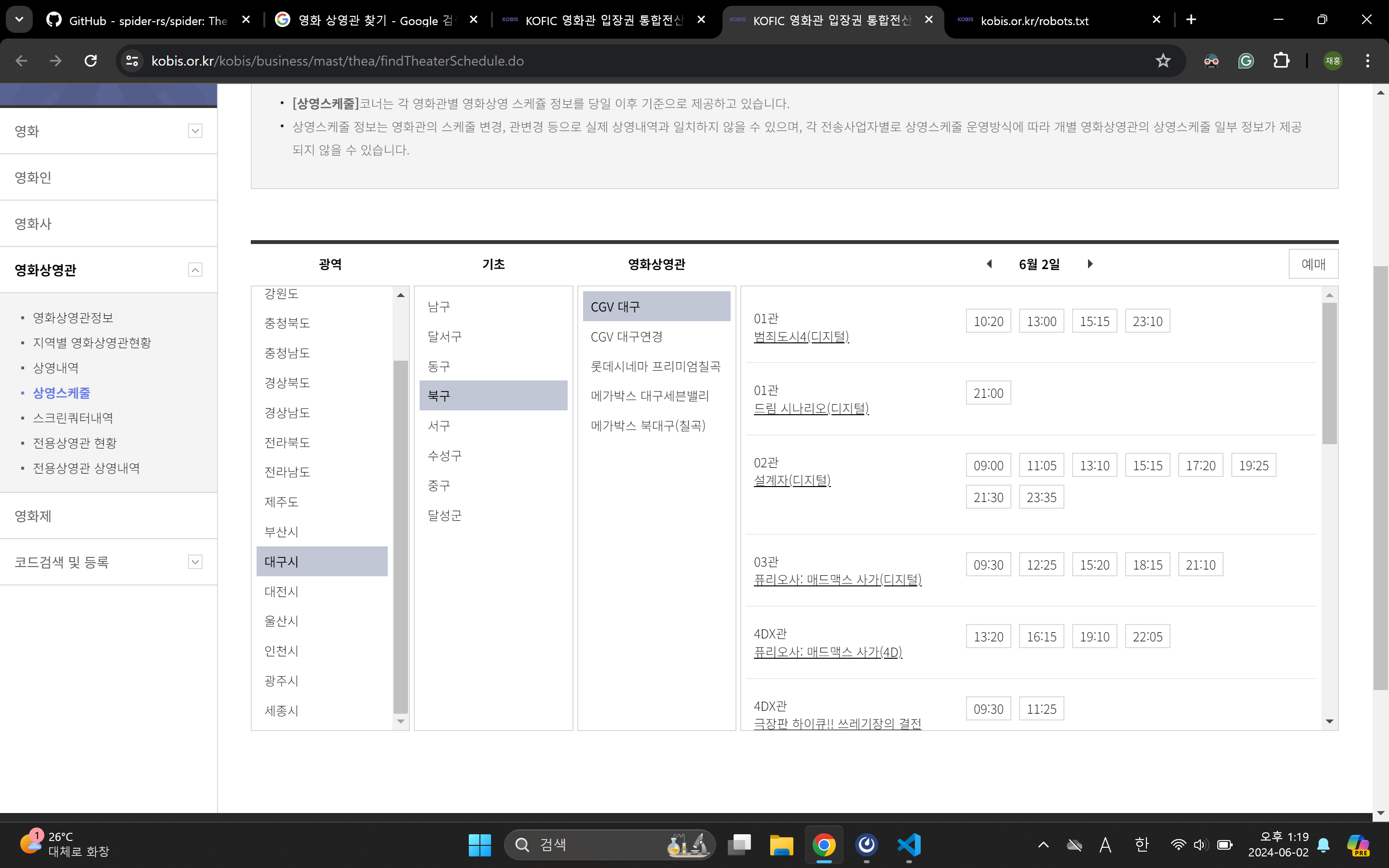
임의의 영화를 상영하는 상영관을 찾을 수도 있습니다.
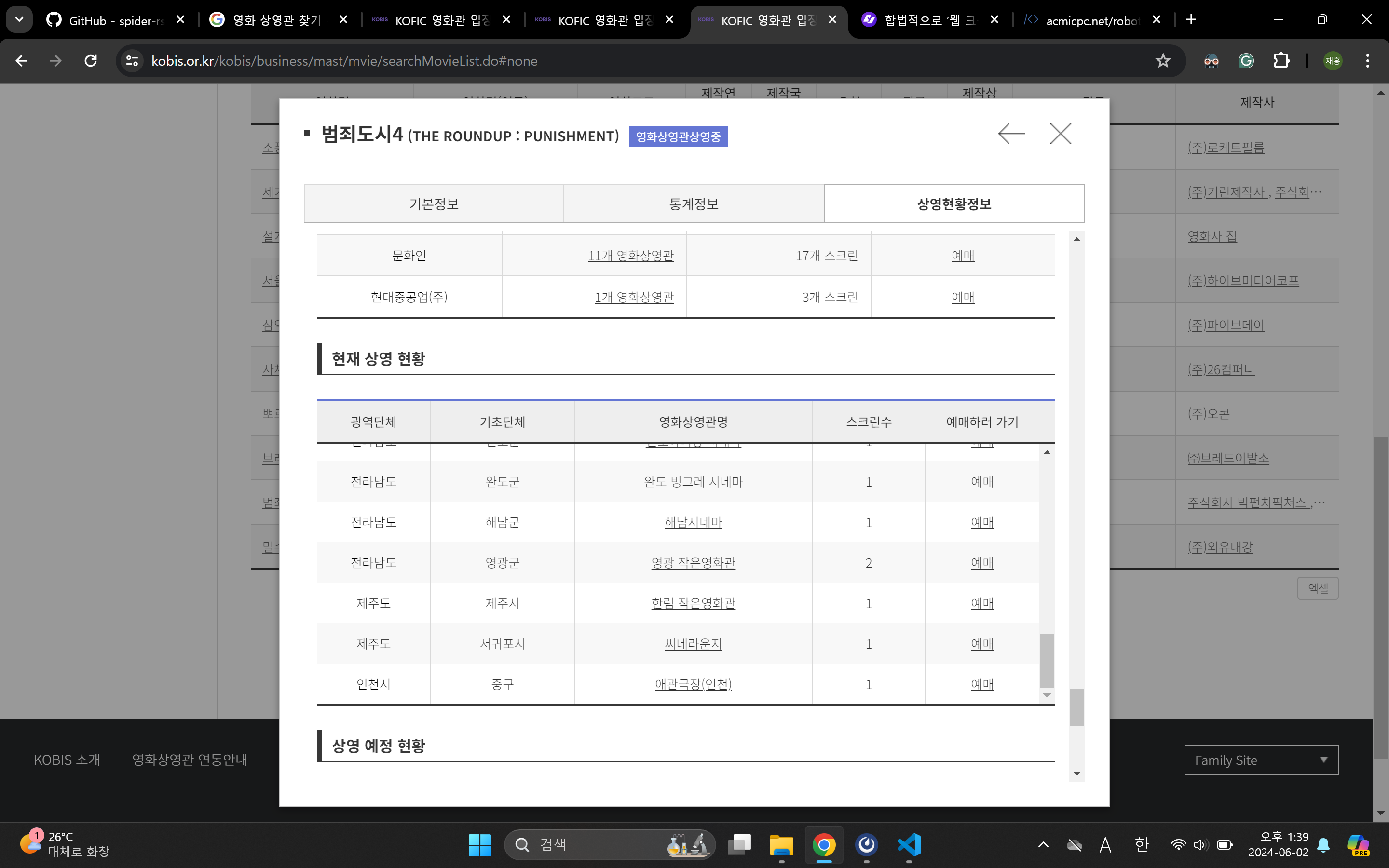
이제 검색 결과를 지도 상에 표시해주도록 만든 후 방구석 라즈베리파이로 배포할 계획입니다. 이 페이지의 모든 검색 결과를 크롤링하면 되겠습니다. 하지만 그 전에 정말 중요한 것 한 가지를 확인해야만 합니다.
크롤링 윤리
크롤링하고자 하는 웹 페이지 최상단(서브 경로 없는 주소)에서 robots.txt를 입력하면 이하 페이지를 볼 수 있습니다.
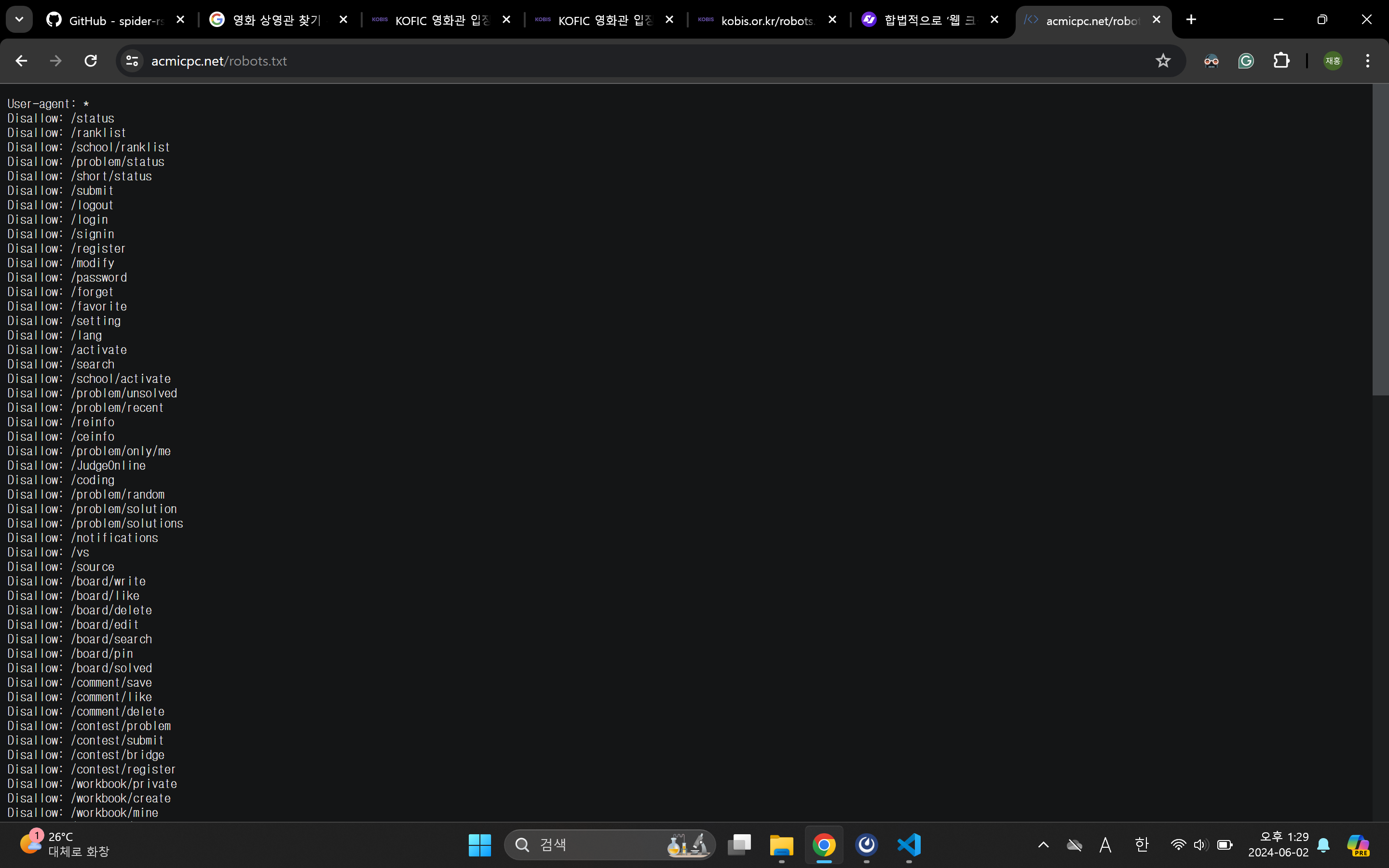
위 페이지는 백준 문제풀이 사이트의 robots.txt입니다. 운영자가 공지사항으로 어떤 형태로든 스크래핑을 금지한다고 했고, 실제 정책을 확인해보면 로그인이 필요한 서비스 전체 및 기타 요청 일부를 robots에 Disallow로 명시해두었습니다.
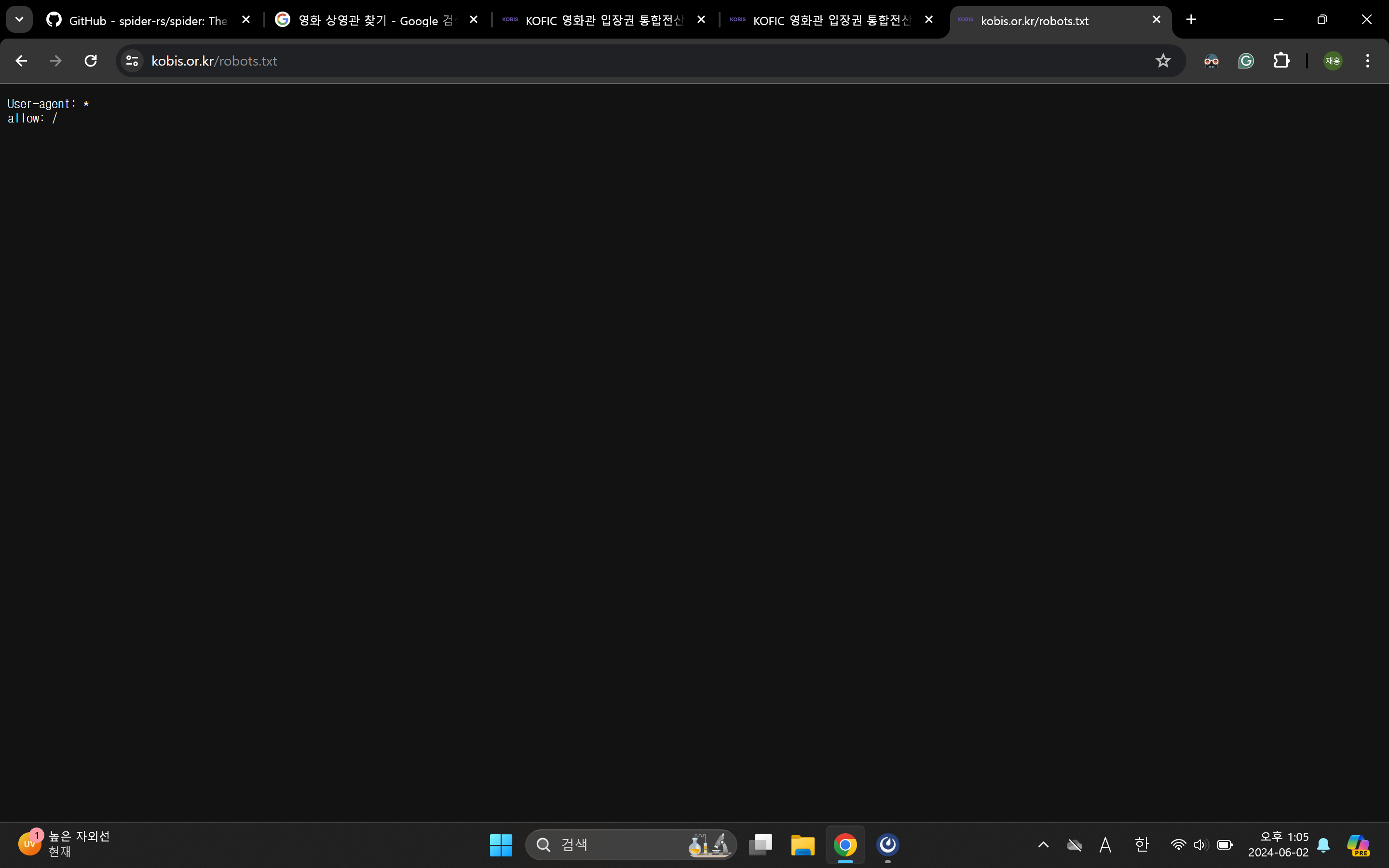
다행히도 KOBIS는 모든 크롤러 및 모든 페이지에 대한 제한이 걸려있지 않습니다.
하지만 robots.txt는 합법적인 크롤링을 위한 여러 조건 중 하나일 뿐입니다. 기타 정책 모두를 확인해보며 실제 크롤링을 해도 될지는 꼼꼼히 따져봐야 합니다. 무차별적인 크롤링은 서버 과부하를 일으키는 공격과 다를 바 없으니까요. KOBIS는 애초에 정보제공을 위한 페이지이므로 어떤 제한을 걸어놓지는 않았습니다. 서버에 부담을 주지 않는 선에서 비영리 목적으로 정보를 모으는 건 크게 문제되지 않습니다.
실제 크롤링은 rust spider 크레이트를 써서 자동화할지 생각중입니다. 크롤링이 실제 필요할지도 좀 검토를 해봐야할 일입니다. 검색 결과를 바로 얻을 수는 있지만 API가 아닌 페이지에서 정보를 스크래핑하는 것이므로 그리 단순하게 결정할 일은 아닐지도 모르겠습니다.