Lego BrickFinder 만들기 - 3.5 가상환경 설정
새로 구한 데이터셋을 넣고 학습시켰습니다.
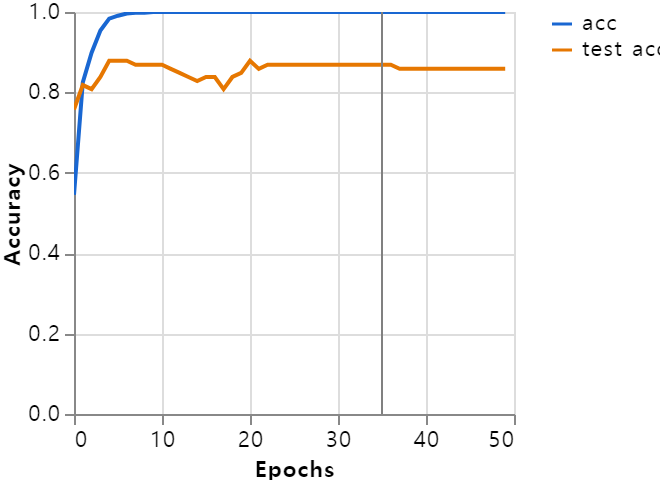
파란 선은 훈련 결과 정확도, 노란 선은 예측을 돌렸을 때의 정확도입니다. 이 모델의 실제 예측은 85% 정도 맞다고 볼 수 있는데, 정작 문제는 훈련 결과입니다. 정확도가 1에 가깝다는 건 그다지 바람직한 결과가 아닙니다. 과대 적합되었을 수 있고, 막상 모델을 써먹었을 때의 정확도는 매우 형편없을 겁니다.
구글 teachable machine을 활용하여 모델을 만들고 로컬에서 활용할 경우 tensorflow 모듈을 써야 합니다. 그런데 이 프레임워크는 파이썬 최신 버전에서는 돌아가지 않습니다. 생각 없이 설치했더니 3.12 버전이 깔려서 여기에 대응을 해야 했습니다.
다른 버전의 파이썬을 쓰려면 일단은 당연히도 설치되어 있어야겠죠. 별도의 폴더에 python 3.9 버전을 설치합니다. 옛날 버전은 간단히 설치할 수도 없고, 파이썬 어카이브를 뒤져야 겨우 파일을 찾을 수 있습니다. 설치 경로는 {user}/Python/으로 했습니다.
파이썬 가상환경을 만드는 방법은 두 가지가 있습니다.
python -m venv {venv}virtualenv {venv}
venv모듈은 파이썬 3.3부터 추가된 내장 모듈로, 가상 환경을 설치할 수 있습니다. 파이썬 버전을 맞춰주려면 명령어에 옵션을 추가하면 됩니다.
py -3.9 -m venv {venv}
생성된 venv 폴더 내의 pyvenv.cfg 파일을 확인해보면 파이썬 버전과 해당 버전의 설치 경로를 확인할 수 있습니다.
home = C:\Users\{user}\Python
include-system-site-packages = false
version = 3.9.0
virtualenv는 기본 내장이 아니므로 pip install virtualenv를 먼저 해주어야 합니다. 버전을 설정하여 가상환경을 생성하려면 다음 명령어를 입력하면 됩니다.
python -m virtualenv --python=3.9 {venv}
보통 검색 결과를 보면 그냥 virtualenv venv만 입력하라고 하는 곳들이 많은데, 적지 않은 경우 command not found 오류와 인사하게 됩니다.
CLI 환경에서 입력하는 명령어의 첫 번째 토큰은 사실 실행시킬 파일의 이름이죠. CLI가 파일을 찾는 기본 경로에 해당 이름이 없으면 환경변수를 뒤지고 그래도 없으면 command not found, 명령어 못 찾겠다!라고 불평해버립니다.
pip으로 모듈이 설치되는 위치는 보통 환경변수로 설정된 파이썬 버전 중 우선순위가 가장 높은 것의 하위 경로입니다. cmd는 여기까지는 뒤져보지 않으니 virtualenv가 없다고 하는 거죠. 이 때 해결 방법은 두 가지입니다.
virtualenv를 usr 경로로 옮기는 등 cmd가 접근 가능하게 한다.python이 대신virtualenv를 실행하게 한다.
첫 번째 토큰으로 python을 넘겨줍니다. 그리고 cmd가 참조 가능한 python은 하위 경로의 virtualenv를 참조할 수 있습니다. 파이썬 명령어의 -m 옵션은 모듈을 실행하라는 뜻입니다.
파이썬 3.9 버전 가상환경이 만들어졌다면 가상 환경을 실행해줍니다.
source {path}/Scripts/activate
모델을 실제로 돌려보니 결과가 그닥 만족스럽지 않습니다.
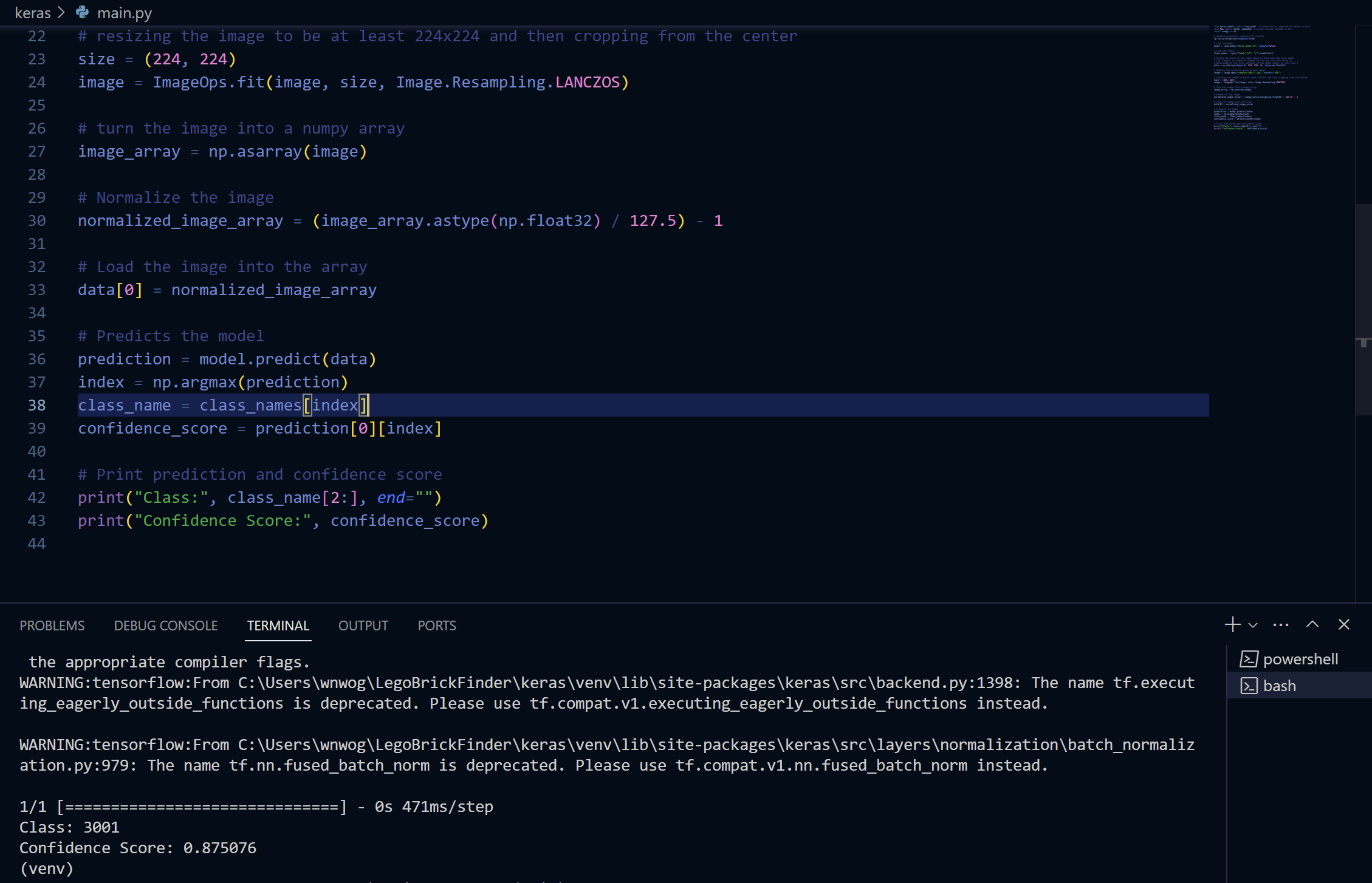
3001 사진을 넣고 돌렸는데 87% 나오네요. 이건 맞히긴 했는데, 다른 브릭들에 대해서는 거의 틀립니다. 새로 데이터를 넣기 전과 마찬가지로 3001 혹은 3004로 판단하는 경향이 있습니다. 딥러닝이란 게 원래 이런 건가 싶네요.
여담으로 YoloV8은 pytorch, teachable machine은 tensorflow 모듈을 기반으로 하는데 두 모듈은 호환성이 매우매우매우 떨어집니다. 삼성 ONE의 실험적 모듈 개발에 참여하면서 여러 딥러닝 프레임워크를 공부했는데, 신경망 파일 포맷의 호환성 때문에 상당히 골치를 썩히고 있었습니다. .onnx라는 오픈소스가 등장하여 포맷 간 호환성을 확보하고 혼돈을 정리해줄 거라 굳게 믿었지만 그러지 못했습니다.
굳건한 1위 tensorflow가 굳이 통합에 발 맞춰줄 필요가 없죠. 사실 내부 문제를 해결하는 것만도 골치 아픈 실정이었습니다. 1.x에서 2.x로 올라갈 때 엄청난 혼란이 있었습니다. 거기에 파이썬이라는 언어 자체도 한 몫 거드는데, 가뜩이나 하위호환성이 형편없는데 버전은 계속 업데이트되니 최대 python3.9까지는 어떻게든 맞춰줬지만 이제는 배째라 하는 실정입니다. 반면 pytorch는 유연함을 무기로 최근 연구에서 사랑받고 있습니다. JAX가 나타났다고는 하지만 아직은 이 두 개가 가장 크지 않나 싶습니다.
슬슬 어떤 모델을 써야할지 결정해야 하는데, 어렵군요. 실제 배포 단계에선 Tensorflow.js로 파일을 변환해서 node로 배포하는 게 가장 간단할 것 같긴 한데요…