Lego BrickFinder 만들기 - 3. 모델 정확도 확보
아무리 좋은 알고리즘을 쓴다고 해도, 결국 딥러닝의 완성도는 데이터에 달렸죠.
마침 Kaggle에 고맙게도 좋은 데이터셋이 있어 가져왔습니다. 찾으면 없는 게 없군요. 다만, 데이터가 3년 전 것이라서 좀 부족할 것 같긴 합니다. 이쪽의 추가 학습은 브릭링크 사이트에서 개인 계정이 올린 사진들을 무작위로 10만 장 정도 긁어온 후 검증을 돌리고, 제대로 분류되지 않은 것들에 대해 labeling 하는 것을 반복하면서… 해보면 되지 않을까 싶습니다..
새로 학습 데이터를 구하긴 했으나 조금 살펴보니 LDD라는 가상 레고 조립 프로그램에서 브릭을 이리저리 돌리면서 배경을 깔아둔 것 같습니다. 정성스럽게 만들어두긴 했는데 이걸 포함시켜서 다시 학습을 시켜도 드라마틱하게 좋은 결과가 나오지는 않았습니다.
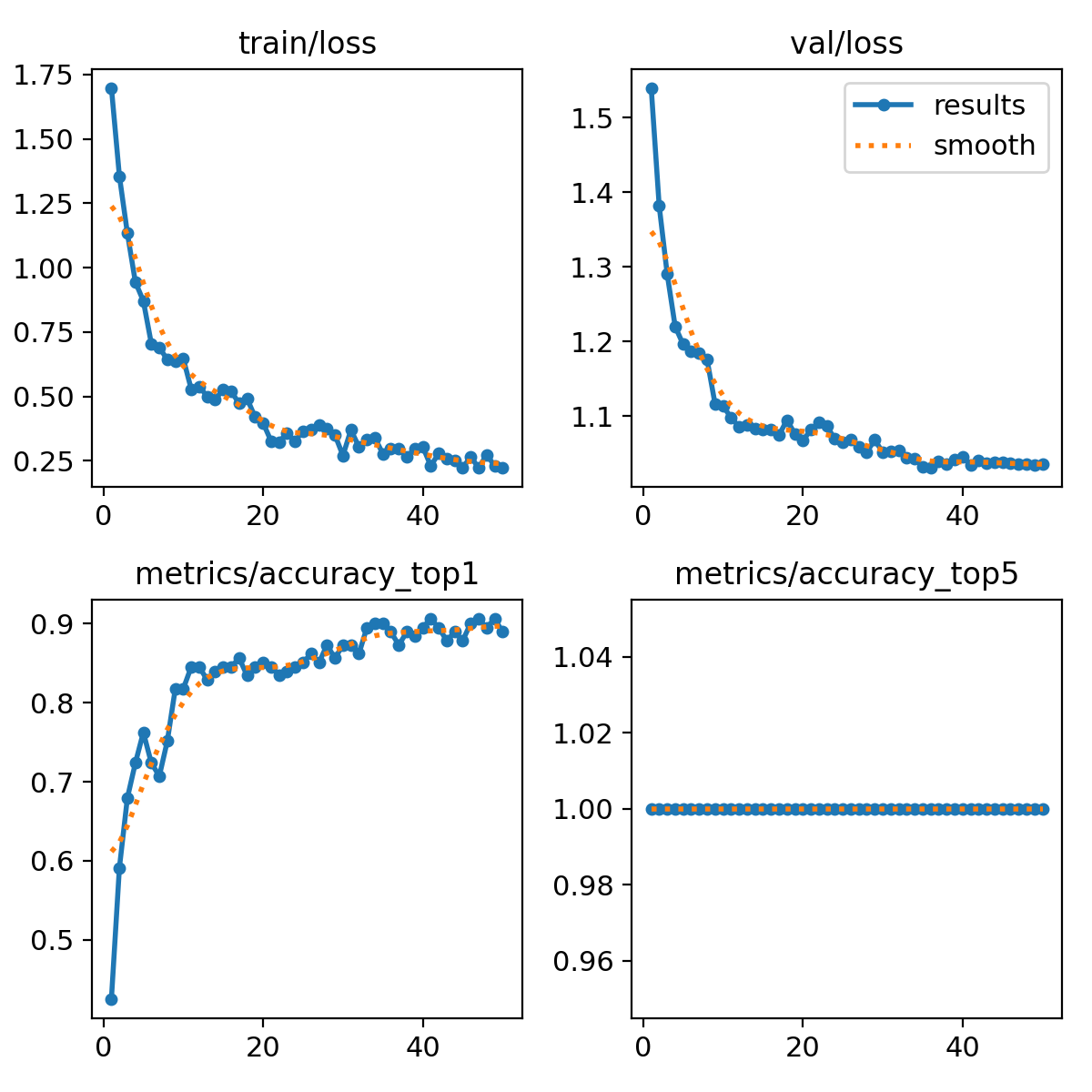
90%까지가 최선인 것 같은데, 그마저도 집에서 찍은 샘플 사진들을 넣고 추론을 돌려보니 대부분 3004 또는 3001로 판단하는 경향을 보였습니다. 뭐가 문제일까요?
실제 배포 단계에서는 구글 teachable machine으로 모델을 생성해볼까 했는데 이게 tensorflow 기반이라 그런지 python 3.12에서는 돌아가지 않습니다. 나중에 3.9버전 환경을 만들고 다시 시도해보거나 다른 모델로 배포를 하거나 해야겠습니다.