Lego BrickFinder 만들기 - 2. YoloV8 모델 학습
이번엔 세 종류 이상의 부품을 구분할 수 있는 모델을 만들어보기로 했습니다.
한 개 이상의 브릭 종류별로 이미지를 자동으로 다운로드 받는 코드를 작성했습니다.
import requests
import os
import random
import shutil
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
PART_IDS = [3001, 3002, 3003, 3004, 3005]
LIST_LEN = 300
OK = 200
TRAIN_RATIO = 0.7
for part_id in PART_IDS:
# 이미지를 저장할 디렉터리 경로
image_folder = f'brick-data/pi-{part_id}'
# 디렉터리가 없으면 생성
if not os.path.exists(image_folder):
os.makedirs(image_folder)
for idx in range(LIST_LEN):
# 브릭 이미지 API
image_url = f'https://img.bricklink.com/ItemImage/PT/{idx}/{part_id}.t1.png'
# HTTP 요청 보내기
response = requests.get(image_url, headers=headers)
# 응답 코드 확인
if response.status_code == OK: # 응답 코드가 200 (OK)일 때만 이미지를 저장
# 이미지 다운로드
image_data = response.content
# 이미지를 브릭 ID로 저장
image_path = os.path.join(image_folder, f'{part_id}-{idx}.png')
with open(image_path, 'wb') as f:
f.write(image_data)
else:
print(f"Failed to download image: {idx}, Status code: {response.status_code}")
# train, val 나눠 담기
train_folder = os.path.join('brick-dataset', 'train', str(part_id))
val_folder = os.path.join('brick-dataset', 'val', str(part_id))
# 디렉토리가 없으면 생성
os.makedirs(train_folder, exist_ok=True)
os.makedirs(val_folder, exist_ok=True)
image_files = os.listdir(image_folder)
# 이미지 파일을 분할 비율에 따라 train과 val에 복사
random.shuffle(image_files) # 파일 목록을 무작위로 섞음
num_train = int(len(image_files) * TRAIN_RATIO) # 학습용 이미지 비율 구하기
train_files = image_files[:num_train] # 슬라이싱
val_files = image_files[num_train:]
# train 폴더에 이미지 복사
for file_name in train_files:
src_path = os.path.join(image_folder, file_name)
dest_path = os.path.join(train_folder, file_name)
shutil.copy(src_path, dest_path)
# val 폴더에 이미지 복사
for file_name in val_files:
src_path = os.path.join(image_folder, file_name)
dest_path = os.path.join(val_folder, file_name)
shutil.copy(src_path, dest_path)
print(f'Images saved to {image_folder}')
Yolo로 학습을 시키기 위해서는 train과 val 하위 경로에 각 카테고리 별로 학습 데이터를 넣어줄 필요가 있습니다. 데이터 포맷을 준비하는 건 꽤 지켜야 할 것이 많지만 실제 학습을 위한 스크립트는 한 두 줄이면 충분합니다.
'''
https://docs.ultralytics.com/ko/tasks/classify/#models
'''
from ultralytics import YOLO
# Load a model
# model = YOLO('yolov8n-cls.yaml') # build a new model from YAML
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
# model = YOLO('yolov8n-cls.yaml').load('yolov8n-cls.pt') # build from YAML and transfer weights
# Train the model
results = model.train(data='./brick-dataset', epochs=20, imgsz=64)
print('train complete')
짧은 코드 몇 줄만 실행해도 알아서 모델 학습이 이루어집니다. 다만 학습 데이터가 썩 풍부하지는 않아서인지 정확도가 90%를 넘지 못하긴 하네요.
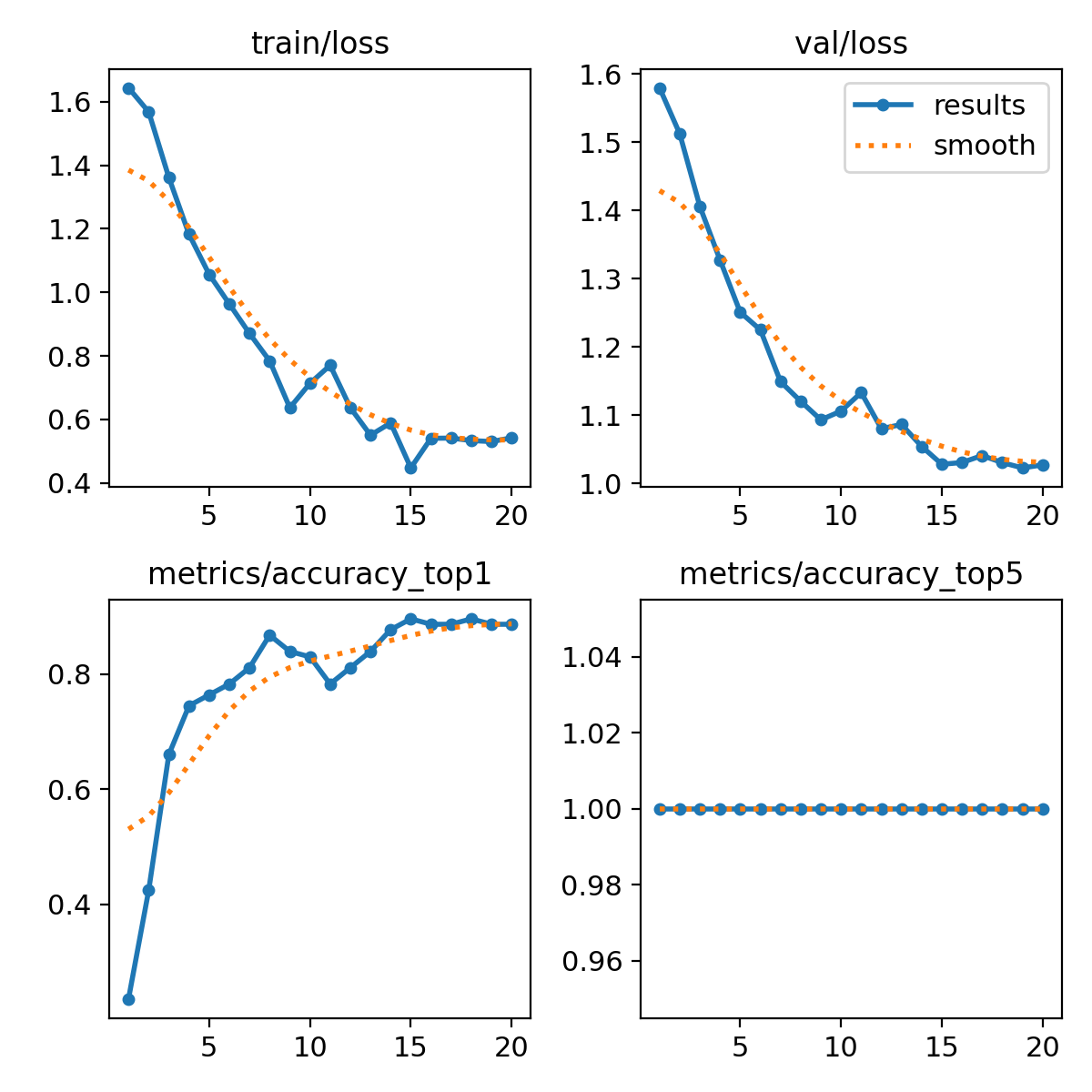
epoch는 학습 횟수를 의미합니다. 횟수가 많을수록 모델은 점차 정확해집니다. 그래프 추이를 봐선 15회 학습 이후로는 손실 함수나 정확도에서 큰 변화를 보이지 않습니다. 학습을 시켰으면 실전으로 넘어가 봅시다. 집에서 아무렇게나 찍은 샘플 사진을 넣고 잘 분류해주는지 확인해보겠습니다. 추론을 위한 코드도 그리 길지 않습니다.

from ultralytics import YOLO
import os
model = YOLO('./../runs/classify/train4/weights/best.pt')
sample_folder = './brick-data/sample'
sample_files = os.listdir(sample_folder)
for sample_file in sample_files:
sample_dir = os.path.join(sample_folder, sample_file)
result = model(sample_dir)
실행 결과는 그닥 좋지 못했습니다.
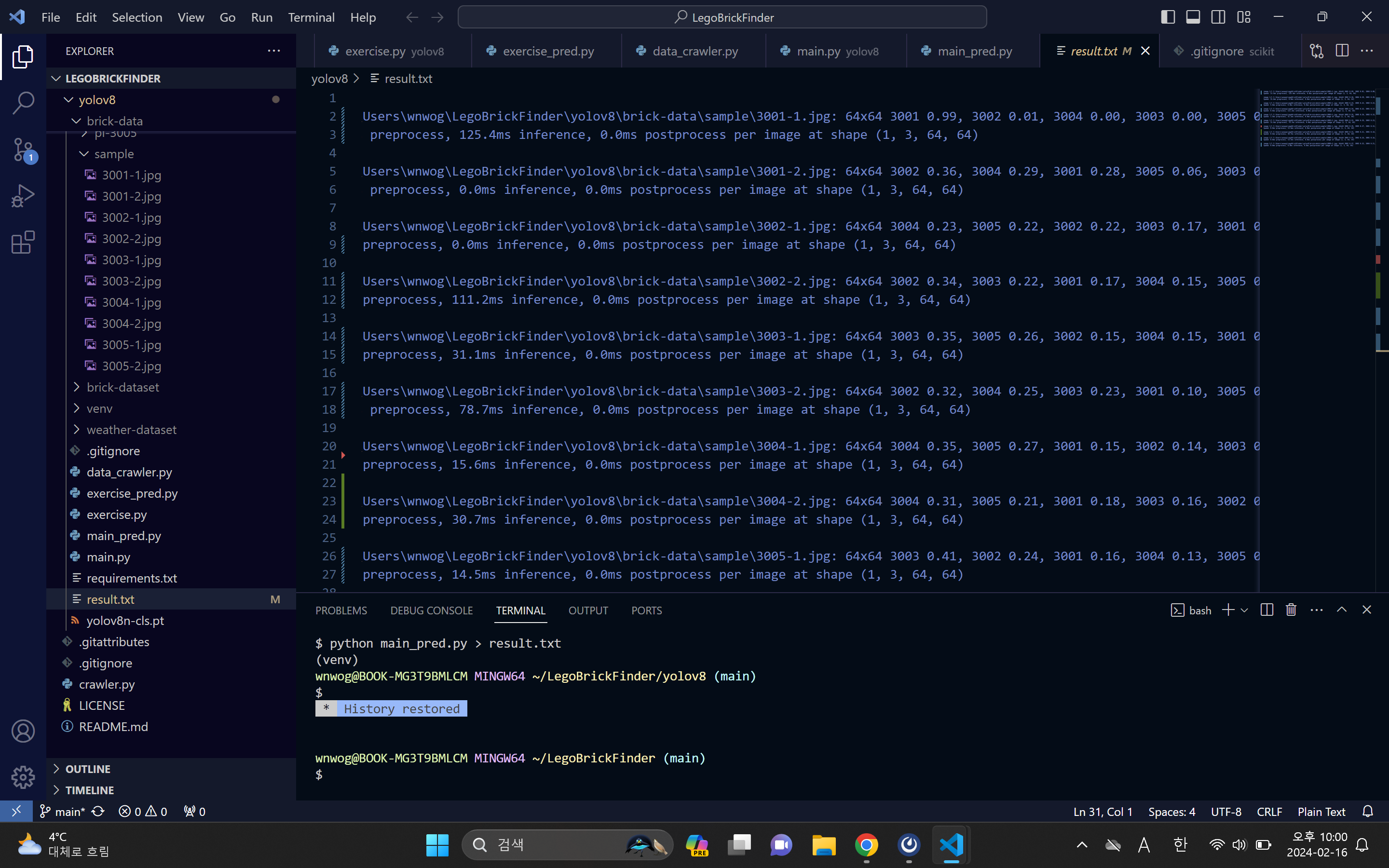
결과를 보니, 3001-1은 99% 확률로 3001번 부품일 것이라고 정확히 추론해냈습니다. 하지만 이건 학습에 쓴 것들과 비슷한 구도로 찍은 사진이라서 그런 건지, 조금 다르게 찍은 사진에 대해서는 20% 언저리로 떨어지는 것을 확인할 수 있습니다. 나머지도 30% 정도 확률로 정답을 찍어맞히긴 하지만 거의 얻어걸린 수준인 것 같습니다. 3005-2 사진은 아예 정답 카테고리일 확률이 5%밖에 되지 않습니다. (어째서?) 3004-1은 아예 눕혀서 찍었기 때문에 당연히 틀릴 것이라 생각했는데 오히려 잡아냈군요. 물론 정확도는 35% 정도로 형편없습니다.
이제 이 프로젝트에서 해결해야 할 가장 시급한 문제는 충분한 정확도를 확보하는 게 되겠네요.