Lego BrickFinder 만들기 - 0. 준비
딥러닝 토이 프로젝트를 하나 진행해보려고 합니다.
- 레고 부품의 사진을 입력받으면
- 부품의 ID를 찾아주는 간단한 딥러닝 모델을 만들고
- 이를 서버에 배포한 후
- 모바일 애플리케이션까지 연동하려고 합니다.
이게 꼭 뭐 수요가 많아서 만든다기보다는, 또 엄청나게 어려운 기술들을 적용해서 만든다기보다는 단지 주변 사람들이 이런 게 있으면 어떨까하고 제안을 해서 만들어보려고 합니다. 물론 제 취미가 레고인 것도 있고, 정말 취업이 잘 안 되니 뭐라도 만들자는 생각도 있지만요.
AI 관련 프로젝트는 삼성 오픈소스 모듈 개발에 참여하면서 간단하게 pytorch나 tensorflow를 만져본 게 전부입니다. 물론 딥러닝이나 CV를 아예 안 해본 것은 아니고, 숫자 구분하는 딥러닝 모델 정도는 하드코딩으로 만들어본 적은 있죠. 이제 좀 더 심도 있게 나아가서 수천 가지의 레고 부품을 구분하는 딥러닝 모델을 만들어보려고 합니다.
학습 모델을 만들기에 앞서, 학습 데이터가 있어야겠죠.
사실 딥러닝 학습자에게 가장 큰 벽이 바로 학습 데이터가 아닐까 생각합니다. 아무리 이론을 잘 공부한다고 하더라도, 방대한 양의 자료로 지도학습을 시킬 수 없다면 네트워크는 텅 빈 채로 남아있게 됩니다.
제 계획은 대충 이렇습니다.
- 부품 이미지: 부품 ID로 짝지어진 데이터 셋을 구합니다.
- 70%는 학습용, 30%는 검증용으로 돌려서 모델을 얻어냅니다.
데이터 셋은 bricklink를 참고하도록 하죠.
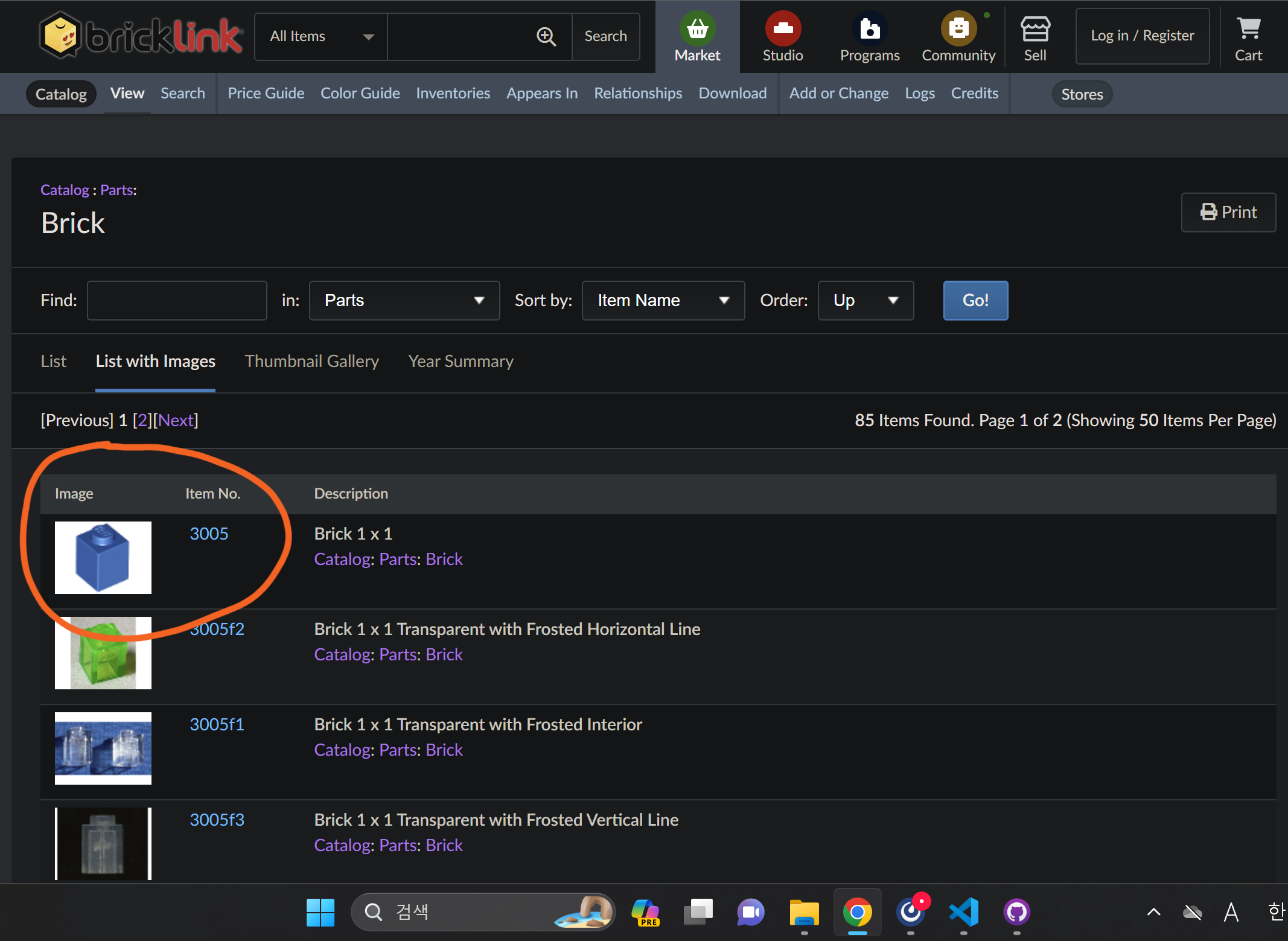
부품 목록을 확인하는 페이지로 들어가면 부품-ID로 이루어진 리스트를 확인할 수 있습니다.
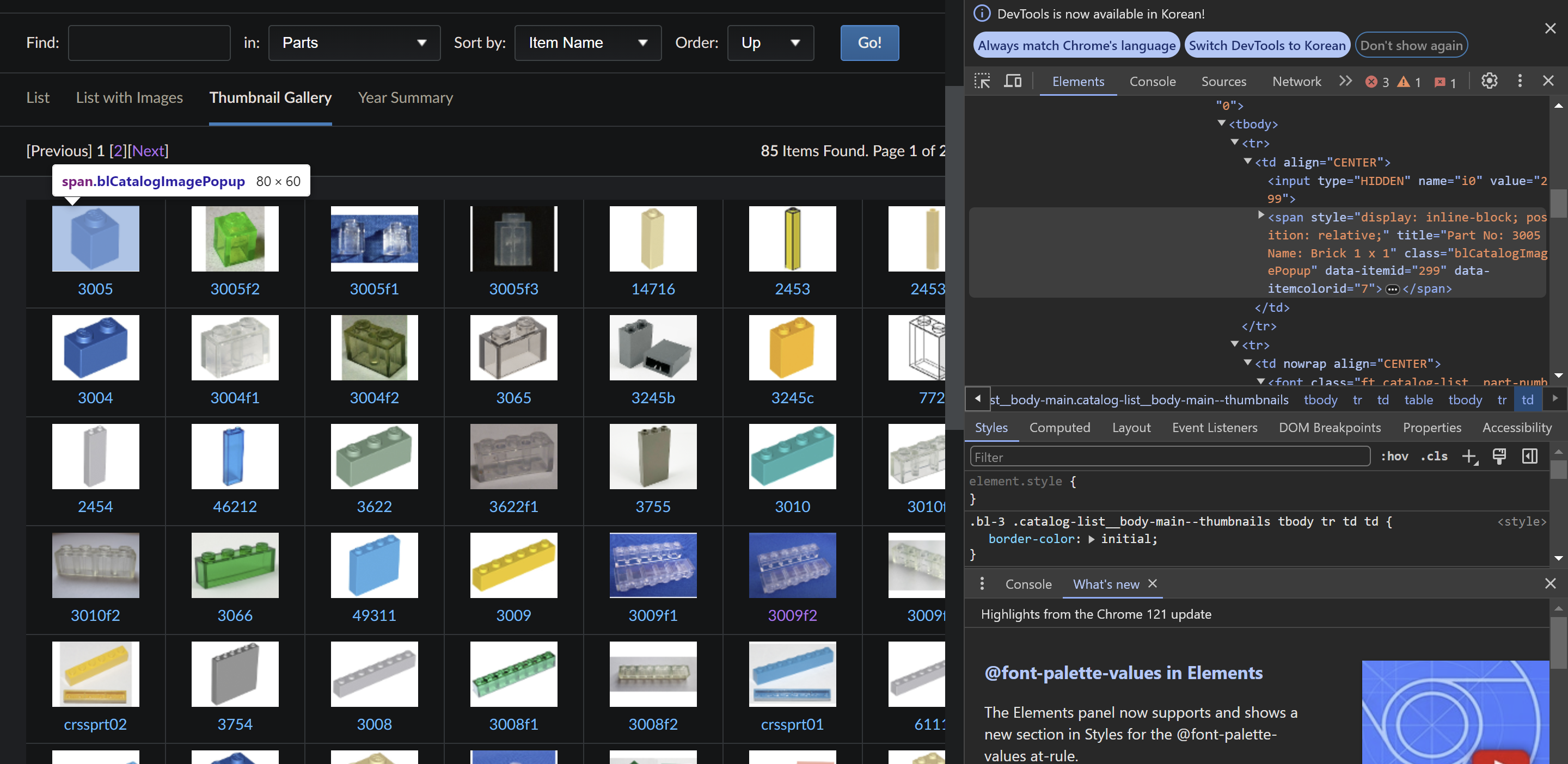
html을 적당히 뜯어보니 쉽게 긁을 수 있을 것 같습니다.
일단 부품 목록을 가져올 수는 있었는데요…
import requests
from bs4 import BeautifulSoup
import os
# 웹 페이지 URL
url = 'https://www.bricklink.com/catalogList.asp?v=2&pg=1&catString=5&catType=P'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
# HTML 요청
# headers를 설정해주지 않으면 403이 반환될 수 있으므로 주의
response = requests.get(url, headers=headers)
# BeautifulSoup 객체 생성
soup = BeautifulSoup(response.text, 'html.parser')
# 클래스가 'blCatalogImagePopup'인 모든 태그 찾기
image_tags = soup.find_all(class_='blCatalogImagePopup')
# 이미지를 저장할 디렉터리 경로
image_folder = 'brick_images'
# 디렉터리가 없으면 생성
if not os.path.exists(image_folder):
os.makedirs(image_folder)
# 이미지 태그를 순회하면서 이미지 다운로드 및 저장
for tag in image_tags:
# 이미지 태그 찾기
img_tag = tag.find('img')
# 이미지 URL 추출
if img_tag:
image_url = img_tag['src']
# 이미지 URL에서 브릭 ID 추출
brick_id = tag['title'].split(' ')[2]
# 이미지 다운로드
image_data = requests.get(image_url).content
# 이미지를 브릭 ID로 저장
image_path = os.path.join(image_folder, f'{brick_id}.jpg')
with open(image_path, 'wb') as f:
f.write(image_data)
print(f'Images saved to {image_folder}')
이렇게만 크롤링을 해놓으니 각 부품별로 이미지가 한 장 뿐입니다. 충분한 학습이 이루어질 수 없습니다. 각 부품들에 대한 서로 다른 이미지들이 필요한데요.
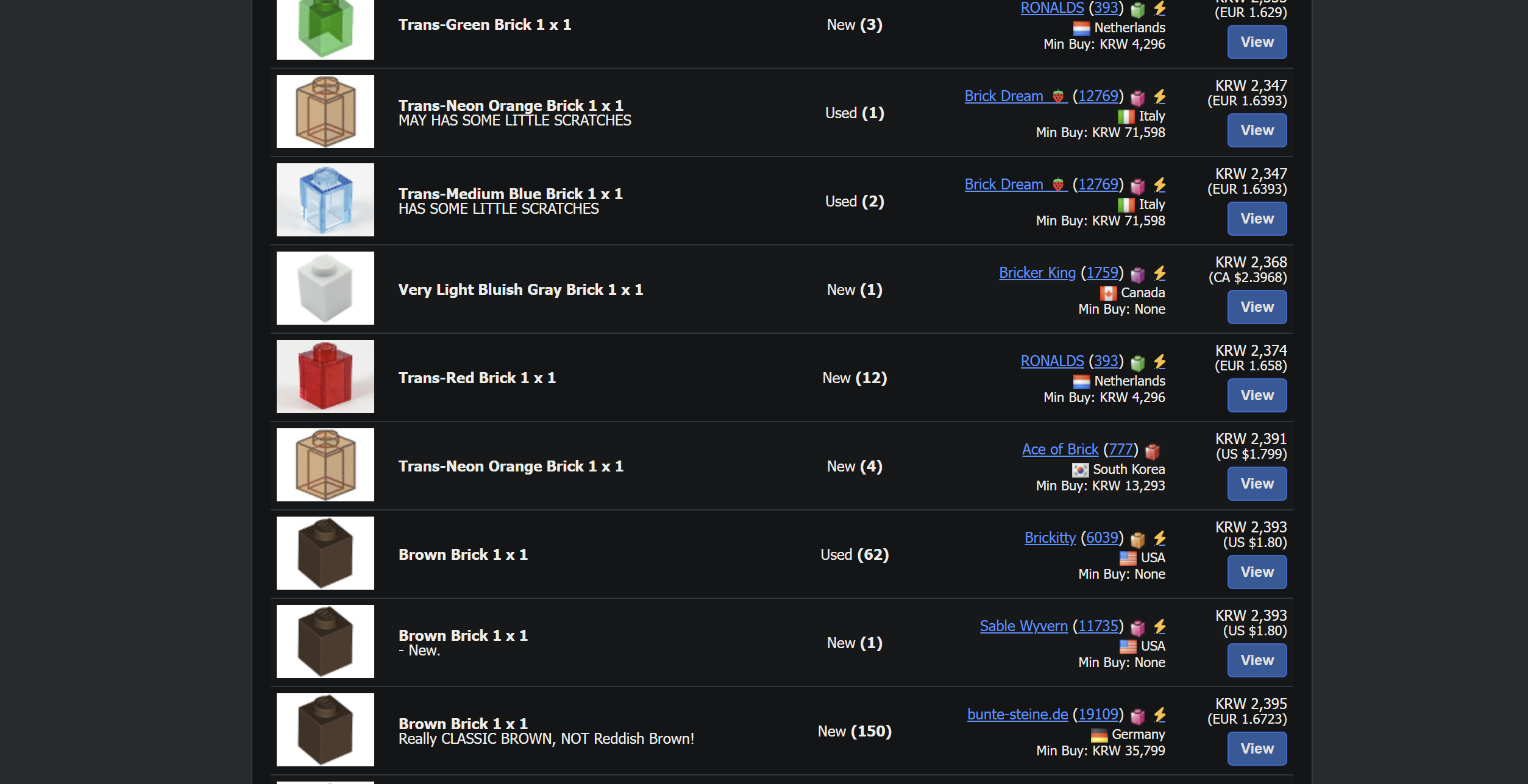
하나의 부품에 대한 검색 결과는 많이 나오기는 하지만 비슷한 샘플 이미지를 돌려 쓴 것들이 많습니다. 과적합 문제가 생길 수도 있으니 크롤링을 한 후에도 충분히 추려내야 할 것 같네요.
일단 이번엔 크게 계획을 짜고, 학습 데이터를 어떻게 구할지만 생각해봤습니다. 다음번엔 scikit이나 yolov으로 뭔가 만들어봐야겠군요.